General Visual Language Model
本文译自Lilian Weng的文章Generalized Visual Language Models,在此感谢她的辛勤创作,献上花花🌸。由于翻译量较大,机翻了部分段落;还有一些术语不知道怎么翻译或者翻译出来怪怪的,都附上英文原文。译者能力有限,恳请读者海涵。
处理图像生成文本,例如看图说话和视觉QA,已经研究了好多年。传统上,这种系统依赖于对象检测网络作为视觉编码器来捕获视觉特征,然后通过文本解码器产生文本。本文总结了现今的不少论文,专注于解决视觉语言任务的一种方法,即扩展预训练的一般语言模型,使其能够处理视觉信号。
我将这种视觉语言模型(VLMs)大致分为四类:
- 将图像转换为可与文本token嵌入联合训练的嵌入特征。
- 学习好的图像嵌入,可以作为固定的、预训练的语言模型的前缀。
- 使用特别设计的交叉注意机制将视觉信息融合到语言模型的各个层中。
- 结合视觉和语言模型,无需任何训练。
图像和文本联合训练
将视觉信息融合到语言模型中的一种直接方法是将图像视为普通的文本token,并在文本和图像的联合表示序列上训练模型。准确地说,图像被分成许多小块(patch),每个小块被视为输入序列中的一个token。
VisualBERT(Li et al. 2019)将文本输入和图像区域都输入到BERT中,这样它就能够通过自注意力发现图像和文本之间的内部对齐。
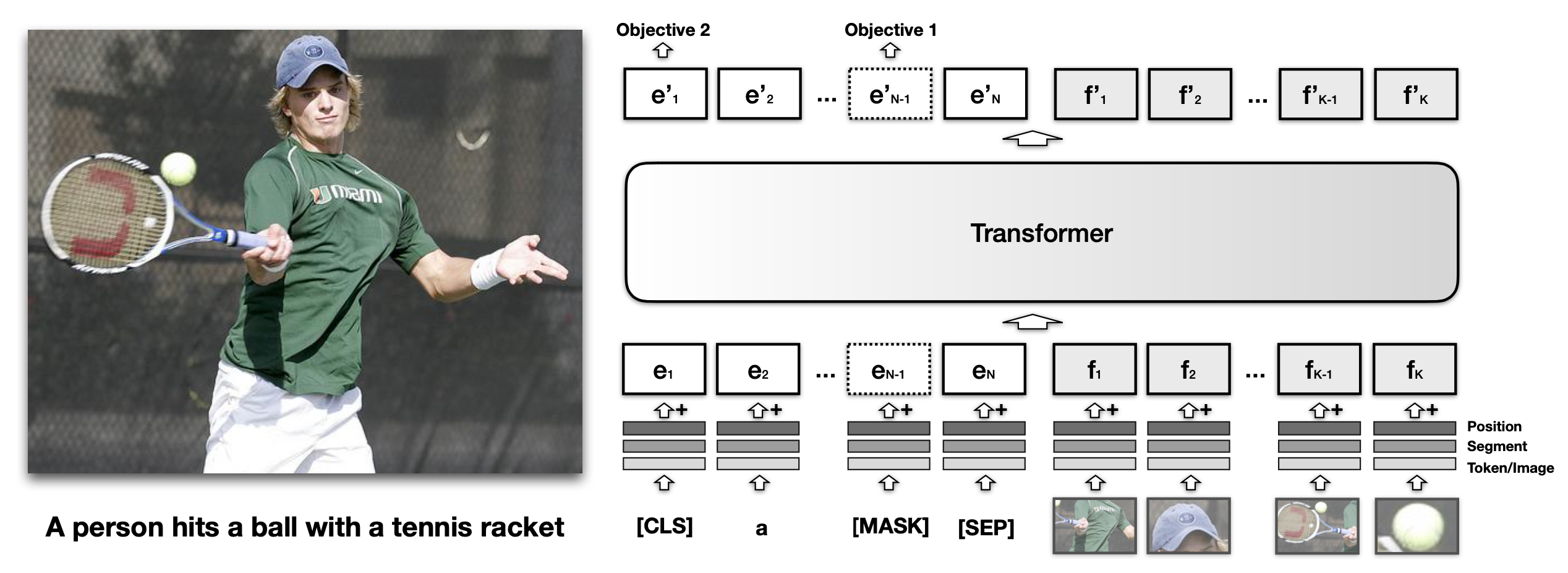
类似于BERT中的文本嵌入,VisualBERT中每个视觉嵌入也是由三种类型的嵌入加和而成的,分别是tokenized特征$f_o$,识别嵌入(segment embedding) $f_s$和位置嵌入$f_p$。具体地:
- $f_o$是觉特征向量,由CNN在一个边界区域上计算得来;
- $f_s$是识别嵌入,用于识别嵌入来自视觉还是文本;
- $f_p$是位置嵌入,用于给边界区域排顺序。
该模型在MS COCO图像标题数据集上训练,文本和图像都作为输入来预测文本描述(caption),使用两个基于视觉的语言模型目标:
- 含图像的掩码语言模型MLM。该模型需要预测文本tokens中的掩码,而图像嵌入始终保持不掩码。
- 句子-图像预测。提供一张图片和两个描述句子,其中一个句子是图片相关的,另一个句子有50%概率相关50%概率随机。模型被要求区分这两种情况。
根据消融实验,最重要的配置是将视觉信息早早融合到transformer层,并在COCO caption数据集上预训练模型。从一个预训练好的BERT初始化以及采用句子-图像预测训练目标,带来的影响相对较小。

VisualBERT在NLVR和Flickr30K上的性能优于SoTA,但在VQA上仍与SoTA存在一定的性能差距。
SimVLM(Simple Visual Language Model;Wang et al. 2022)是一个简单的前缀语言模型,其中前缀序列像BERT一样用双向注意力处理,但主输入序列像GPT一样只有因果注意力。图像被编码为前缀token,这样模型就可以完全采纳视觉信息,然后以自回归的方式生成相关的文本。
受ViT和CoAtNet的启发,SimVLM将图像分割成更小的块,并展成一维小块序列。他们使用由ResNet的前3个块组成的卷积步骤来提取包含上下文信息的小块,这种设置被发现比平凡的线性投影更好。

SimVLM的训练数据包括来自ALIGN(Jia et al. 2021)的大量图像-文本对和来自C4数据集(Raffel et al. 2019)的纯文本数据。他们在每个小批量(batch)中混合了两个预训练数据集,包含4096个图像-文本对(ALIGN)和512个纯文本文档(C4)。
根据消融实验,同时拥有图像-文本和纯文本数据进行训练是很重要的。前缀语言模型目标优于span corruption和普通语言模型。
